昨年12月に Dataform の Google Cloud 加入が発表 されて以来, 関心を持って調べています. Dataform は BigQuery などのデータウェアハウス上で SQL を中心としたデータ変換パイプラインを構築するための仕組みです.
先日は Dataform で Google Analytics 4 の BigQuery Export データ を変換するパイプラインを作ってみたりもしました(GitHub: terashim/dataform-google-analytics-4-example).
Dataform は非常に強力なツールで, 簡単な SELECT 文を書けば CREATE TABLE 文や MERGE 文などデータ更新用のクエリを自動生成してくれます. しかし詳しく調べていくにつれて, より本格的なパイプラインを構築するにはやはり BigQuery 自体の挙動についてよく理解しておくことが重要だと感じるようになりました.
BigQuery はクエリで処理されたデータ量に応じて料金が発生するため, 処理されるデータ量が大きくならないように注意する必要があります. 特に BigQuery 上でデータ変換パイプラインを構築する場合はクエリを定期的に自動実行することになるので, 事前の準備が重要になります.
多量のデータを持つテーブルを作成するとき, そのテーブルに対するクエリのデータ量を抑えるために パーティション分割テーブル がよく用いられます. そこでこの記事では BigQuery 上で SQL によるデータ変換パイプライン構築を行う場面を想定してパーティションの利用法や注意点について整理します.
基本
パーティションとは
BigQuery 公式ドキュメント "パーティション分割テーブルの概要" には
パーティション分割テーブルはパーティションと呼ばれるセグメントに分割された特殊なテーブルで、データの管理や照会をより簡単に行うことができます。大きいテーブルを小さいパーティションに分割することでクエリのパフォーマンスを向上させることができ、クエリで読み取られるバイト数を減らすことによってコストを管理できます。
とあります. パーティショニングの種類には
- 取り込み時間分割テーブル
- 時間単位の列パーティション分割テーブル
- 整数範囲パーティション分割テーブル
の3つがあります. 以下では時間単位の列パーティション分割テーブルの例だけを考えますが, 他の種類でも考え方は共通です.
次に具体的な例を示します.
パーティションのプルーニング
例として, あるシステムで発生したイベントログを格納したテーブル event_log を考えます.
このテーブルはイベント発生時刻のタイムスタンプ event_timestamp, ユーザーID user_id, および発生したイベントの内容 event の3つの列を持つとします.
このテーブルの内容は例えば次のような形になります:
event_timestamp | user_id | event
:-------------------|:--------|:--------------
... | ... | ...
2020-12-31 10:00:00 | 100 | ページAを閲覧
2020-12-31 14:50:00 | 200 | ページBを閲覧
2021-01-01 10:30:00 | 100 | 商品Aを購入
2021-01-01 18:45:00 | 300 | ページBを閲覧
... | ... | ...
さらに, このテーブルはタイムスタンプ列 event_timestamp で日付ごとにパーティショニングされているものとします.
このテーブルに対して次のようなクエリを実行すると, すべてのパーティションがスキャンされます:
SELECT
event_timestamp,
user_id,
event
FROM
event_log
WHERE
event = "商品Aを購入"
もしこのテーブルに長期間にわたるイベントログが多量に格納されていると, このクエリで処理されるデータ量は非常に大きくなる可能性があります.
もし過去の情報に興味がなく最近のデータを検索するだけで十分ならば,
次のように列 event_timestamp に関する条件を付けることでクエリのデータ処理量を抑えることができます:
SELECT
event_timestamp,
user_id,
event
FROM
event_log
FROM
events
WHERE
event = "商品Aを購入"
AND event_timestamp >= "2021-01-01" -- 検索対象のパーティションを絞り込む
このようにスキャン対象のパーティションを絞り込むことをパーティションの プルーニング と言います.
動的なプルーニング条件
プルーニングの条件を別のテーブルから読み取ったパラメータなどから動的に決めたい場合があります.
このとき例えば
SELECT
event_timestamp,
user_id,
event
FROM
event_log
WHERE
timestamp >= (SELECT MAX(event_timestamp) FROM other_table)
のように プルーニングの条件にサブクエリを使うと効果が得られません.
このような場合は次のように BigQuery スクリプト の DECLARE 文でサブクエリの内容を変数に格納すればプルーニングの効果が得られるようになります(参考: Xinran Waibel "BigQuery Best Practices | Google Cloud - Community").
-- いったん変数 event_timestamp_pruning_threshold に値を格納する
DECLARE event_timestamp_pruning_threshold DEFAULT (
SELECT MAX(event_timestamp) FROM other_table
);
SELECT
event_timestamp,
user_id,
event
FROM
event_log
WHERE
event_timestamp >= event_timestamp_pruning_threshold -- プルーニングが有効になる
MERGE 文
SQL でパイプラインを構築するとき, 大きなサイズのテーブルについてはデータの 差分更新 を行います.
差分更新を行うためにはいわゆる "UPSERT", つまり差分データのうち既に更新対象のテーブル上に存在する行については上書き更新を, まだ存在しない行については新規挿入を行うという操作が必要になります.
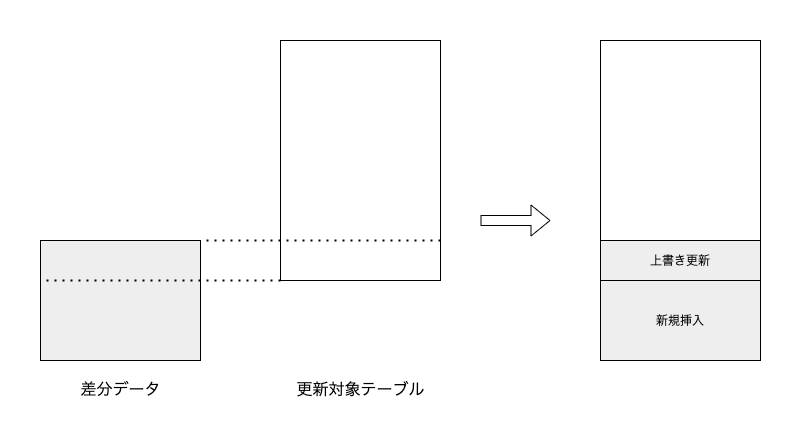
図: テーブルの差分更新
このような操作を実現する手段として BigQuery は MERGE 文 をサポートしているので, 差分更新にはこれを利用します.
例えば, イベントログのテーブル event_log を新しいデータ new_event_log で差分更新するクエリは次のようになります:
MERGE event_log AS T -- 更新対象のテーブル
USING new_event_log AS S -- 差分データ
ON
-- 更新/挿入の判定条件
T.event_timestamp = S.event_timestamp
AND T.user_id = S.user_id
AND T.event = S.event
WHEN MATCHED THEN
-- 行が一致する場合は上書き更新
UPDATE
T.event_timestamp = S.event_timestamp,
T.user_id = S.user_id,
T.event = S.event
WHEN NOT MATCHED THEN
-- 一致しない場合は新規挿入
INSERT
(event_timestamp, user_id, event)
VALUES
(
S.event_timestamp,
S.user_id,
S.event
)
MERGE 文のプルーニング条件
MERGE 文でテーブルを差分更新するときには, 差分データと既存の行が一致するかどうかのチェックを行うために更新対象テーブルへのスキャンが発生します.
このときにもすべてのパーティションがスキャンされると処理されるデータ量が大きくなってしまいます.
この問題を避けるには WHEN MATCHED AND 〈プルーニング条件〉 THEN ... の構文を使ってチェック対象のパーティションをプルーニングします.
(参考: "DML を使用したパーティション分割テーブルデータの更新 | BigQuery | Google Cloud")
これを使って上の例を修正すると, 例えば次のようになります
MERGE event_log AS T -- 更新対象のテーブル
USING new_event_log AS S -- 差分データ
ON
-- 更新/挿入の条件判定
T.event_timestamp = S.event_timestamp
AND T.user_id = S.user_id
AND T.event = S.event
-- 対象パーティションを限定して一致判定
WHEN MATCHED AND T.event_timestamp >= "2021-01-01" THEN
-- 行が一致する場合は上書き更新
UPDATE
T.event_timestamp = S.event_timestamp,
T.user_id = S.user_id,
T.event = S.event
WHEN NOT MATCHED THEN
-- 一致しない場合は新規挿入
INSERT
(event_timestamp, user_id, event)
VALUES
(
S.event_timestamp,
S.user_id,
S.event
)
この場合, 差分データ new_event_log に 2021/01/01 より前のデータが入っていると重複が発生してしまう可能性もあります.
パイプラインの構築
パイプラインの基本単位
パイプライン構築では, 読み取り元テーブルからデータを取り出し, 適当に加工して更新対象テーブルに書き込む処理が基本単位となります.
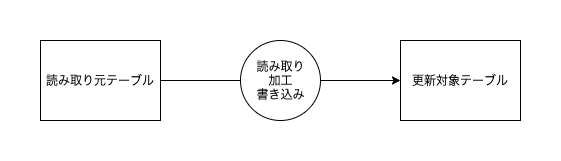
図: パイプラインの基本単位
このような処理を複数組み合わせて順序良く実行していくことで全体がパイプラインとして機能するようになります. このとき処理が上流から下流へと順番通りに実行されるよう依存性管理が必要になります. これには Dataform または他のワークフロー管理ツール(Airflow など)を使いますが, この記事では扱いません.
テーブルの更新方法には大きく分けて全件更新と差分更新の2つがあります. イベントログのように日々追加されていくデータを扱う際には通常差分更新を行います.
このような差分更新処理を行うためのクエリは次のような形になります:
MERGE {{更新対象テーブル}} AS T
USING (
{{読み取り元テーブルのデータを読み取り, 加工して差分データを作成するサブクエリ}}
) AS S
ON
{{更新/挿入の条件判定式}}
WHEN MATCHED AND {{更新対象パーティションの絞り込み条件}} THEN
{{更新する行についての UPDATE 文}}
WHEN NOT MATCHED THEN
{{挿入する行についての INSERT 文}}
単純な例
イベントログ event_log を集計して日次サマリテーブル daily_event_summary を作成する場面を考えます
日次サマリテーブル daily_event_summary は日付 date, イベント event, イベントの発生回数 event_count の3列を持つとします. このテーブルの内容は例えば次のような形になります:
date | event | event_count
:-----------|:--------------|:------------
... | ... | ...
2020-12-31 | ページAを閲覧 | 1000
2020-12-31 | ページBを閲覧 | 800
2020-12-31 | 商品Aを購入 | 15
2021-01-01 | ページAを閲覧 | 1500
2021-01-01 | ページBを閲覧 | 2100
2021-01-01 | 商品Aを購入 | 8
... | ... | ...
また, このテーブルは列 date でパーティショニングされているものとします.
このとき,
イベントログテーブル event_log から昨日1日分のデータを読み取り,
集計して日次サマリテーブル daily_event_summary を1日分だけ差分更新するクエリは次のようになります
MERGE daily_event_summary AS T
USING (
-- 昨日1日分のイベントログデータを集計するサブクエリ
SELECT
DATE(event_timestamp) AS date,
event,
COUNT(*) AS event_count
FROM
event_log
WHERE
-- 読み取るデータを昨日の日付に限定
DATE(event_timestamp) = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
GROUP BY
DATE(event_timestamp),
event
) AS S
ON
-- 更新/挿入の条件判定
T.date = S.date
AND T.event = S.event
-- 対象パーティションを昨日の日付に限定して一致判定
WHEN MATCHED AND T.date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY) THEN
-- 行が一致する場合は上書き更新
UPDATE
T.date = S.date,
T.event = S.event,
T.event_count = S.event_count
WHEN NOT MATCHED THEN
-- 一致しない場合は新規挿入
INSERT
(date, event, event_count)
VALUES
(
S.date,
S.event,
S.event_count
)
サブクエリ中のデータ読み取りと MERGE 文による一致判定の両方でパーティションをプルーニングしていることに注意してください(下図参照). このクエリを毎日定期的に実行すれば前日のイベントが日次サマリテーブルに自動で反映されるようになります.
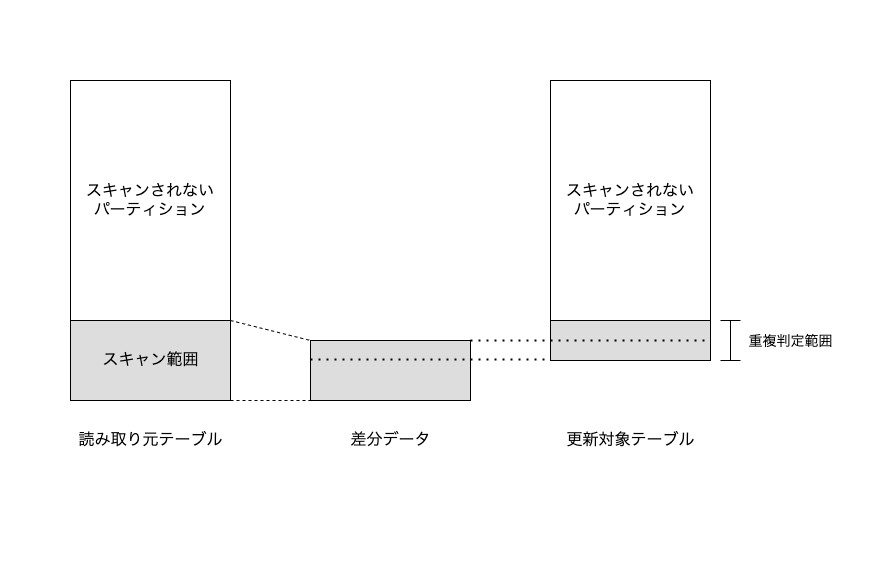
図: 読み取り元テーブルと更新対象テーブルに対するパーティションのプルーニング
更新範囲を動的に決定する
上の例では処理対象のパーティションを昨日の日付に限定しましたが, 実際のパイプラインでは過去の日付のデータを処理したい場合があります. 例えば
- しばらくパイプラインが停止していて, 後から再開したいとき
- パイプライン上流から読み取り元テーブルへのデータ供給に遅延があったとき
- 過去の日付で作成したテスト用データを使ってテストを行いたいとき
- パイプラインの変換ロジックを変更して過去データの変換を最初からやり直したいとき
などです.
そのため, パーティションのプルーニング条件指定は現在の日付 CURRENT_DATE() や現在時刻 CURRENT_TIMESTAMP() に依存しないほうが望ましいと言えます.
これを実現するには, 対象パーティション範囲を更新対象テーブルのデータを見て決める方法が考えられます.
次のクエリでは日次サマリテーブル daily_event_summary に既に書き込まれているデータのうち最新の日付を取ってきて, それ以降のデータを差分更新します:
-- 既に集計済みのデータの中から最新の日付を取得
DECLARE start_date DEFAULT (
SELECT MAX(date) FROM daily_event_summary
);
MERGE daily_event_summary AS T
USING (
-- イベントログを集計して差分データを作成するサブクエリ
SELECT
DATE(event_timestamp) AS date,
event,
COUNT(*) AS event_count
FROM
event_log
WHERE
-- 読み取るデータを限定
DATE(event_timestamp) >= start_date
GROUP BY
DATE(event_timestamp),
event
) AS S
ON
-- 更新/挿入の条件判定
T.date = S.date
AND T.event = S.event
-- 対象パーティションを限定して一致判定
WHEN MATCHED AND T.date >= start_date THEN
-- 行が一致する場合は上書き更新
UPDATE
T.date = S.date,
T.event = S.event,
T.event_count = S.event_count
WHEN NOT MATCHED THEN
-- 一致しない場合は新規挿入
INSERT
(date, event, event_count)
VALUES
(
S.date,
S.event,
S.event_count
)
ここで DACLARE 文を使って変数 start_date に日付を格納していることに注意してください.
上述のようにここで変数に格納せずサブクエリを使ってしまうとプルーニングの効果が得られません.
(参考) Dataform の場合
参考までに, Dataform を使う場合は SQLX(SQLの拡張言語)で以下のように書くと上のような MERGE 文が自動的に生成されます.
-- daily_event_summary.sqlx
config {
type: "incremental",
uniqueKey: ["date", "event"],
bigquery: {
partitionBy: "date",
updatePartitionFilter: "date >= start_date"
}
}
pre_operations {
-- 既に集計済みのデータの中から最新の日付を取得
DECLARE start_date DEFAULT (
${when(incremental(),
`SELECT MAX(date) FROM daily_event_summary`,
`SELECT DATE("2000-01-01")`
)}
);
}
-- イベントログを集計して差分データを作成するクエリ
SELECT
DATE(event_timestamp) AS date,
event,
COUNT(*) AS event_count
FROM
event_log
WHERE
-- 読み取るデータを限定
DATE(event_timestamp) >= start_date
GROUP BY
DATE(event_timestamp),
event
(参考: "Google BigQuery | Dataform", "Incremental datasets | Dataform" )
まとめ
- BigQuery ではクエリの処理量を抑えるためパーティションのプルーニングを行います
- データの差分更新には MERGE 文を利用します
- MERGE 文では読み取り元テーブルと書き込み先テーブルの両方に対してパーティションのプルーニングを行います
- プルーニングの条件にサブクエリを使うと効果が得られないので, DECLARE 文でいったん変数に格納します