R のパイプラインツール targets をデータ分析プロジェクトで採用する意義と、そのときに推奨される関数型のプログラミングスタイルについてまとめました。
targets とは
targets は "R による統計・データサイエンスのための Make 風パイプラインツール" です。
R のパイプラインツールとしては以前から drake がありましたがこちらは既に開発が停止されており、現在はその後継プロジェクトとして targets が開発されています。
パイプラインツールの種類と targets の位置づけ
一般的に次のような特徴を持つものがパイプラインツールと呼ばれています
- 一連の処理を複数のタスクの集まりとして定義する
- タスク間の依存関係を考慮し、正しい順序で実行する
- タスクをキャッシュしたり並列化したりして効率的に実行する
パイプラインツールの代表的な利用シーンとしては次のようなものがあります
- ソフトウェアのビルド
- データパイプライン
- 機械学習パイプライン
targets は自らを R 言語で使える Make 風のパイプラインツールと位置づけています。ただ Make はソフトウェアのコンパイルに利用されることが多いのですが、targets の利用シーンとしてはデータ分析プロジェクトが想定されています。
データ分析には長時間の処理が含まれることが多く、コードを修正する度に一からすべての処理を再実行していては開発に時間が掛かり過ぎてしまいます。targets は依存関係管理とキャッシュ機構によってこれを解決することを目指しています。
targets の学習資料
targets の仕組みや使い方を学ぶには、以下の資料が特に優れています
- 公式ユーザーマニュアル The targets R Package User Manual
- 特にチュートリアルの章 Chapter 2 Walkthrough
- パッケージ作者 W. Landau 氏によるウェビナー動画 New York Open Statistical Programming Meetup, December 2020 (1:54:28)
残念ながら現在のところ targets に関する日本語資料は見当たらりません。前身の drake については次の記事があります。
(2022/06/06 追記) その後、日本語でも
- {targets}でワークフローを管理せよ / Workflow management with targets - Speaker Deck https://gihyo.jp/book/2022/978-4-297-12524-0
の発表があり、書籍
でも targets が取り上げられました。
targets の基本構造
targets プロジェクトは次のような要素で構成されます
- パイプライン
- 一連の処理全体をパイプラインと呼びます。パイプラインは target スクリプトファイル(デフォルトでは
_targets.R)で定義されます。
- 一連の処理全体をパイプラインと呼びます。パイプラインは target スクリプトファイル(デフォルトでは
- ターゲット
- パイプラインに含まれる各ステップの処理をターゲットと呼びます。ターゲットは
tar_target()関数 で作成します。各ターゲットは固有の名前とコマンドを持ちます。
- パイプラインに含まれる各ステップの処理をターゲットと呼びます。ターゲットは
- データストア
- ターゲットの出力やメタデータが保存される場所をデータストアと呼びます。デフォルトでは
_targets/フォルダがデータストアとして利用されます。
- ターゲットの出力やメタデータが保存される場所をデータストアと呼びます。デフォルトでは
targets は静的コード解析によってターゲット間の依存関係を解析し、実行順序を決定します。パイプラインを実行するとこの順序にしたがって各ターゲットのコマンドが呼び出され、その出力がデータストアに保存されます。
もう一度パイプラインを実行したとき、前回と比べてターゲットの定義に変更がある場合はそのターゲットとそれに依存する下流ターゲットのコマンドが再実行されます。再実行の必要がないターゲットについてはデータストアに保存された値が再利用されます。これによって時間の掛かる処理をスキップすることができます。
公式チュートリアル の例では、ターゲットの依存関係は次のグラフのようになります。
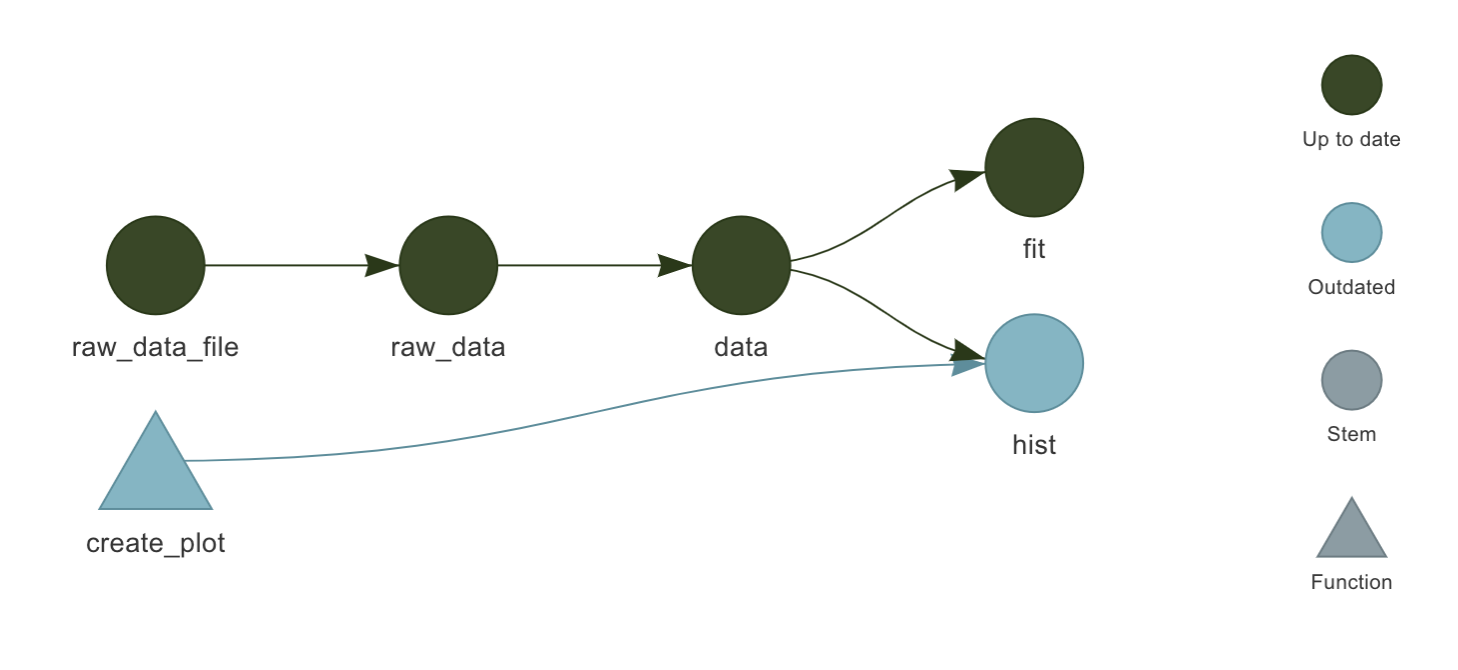
図: ターゲットの依存関係を可視化したグラフ
このパイプラインは次のような targets スクリプトファイル _targets.R によって定義されます。
# _targets.R file
library(targets)
source("R/functions.R")
options(tidyverse.quiet = TRUE)
tar_option_set(packages = c("biglm", "tidyverse"))
list(
tar_target(
raw_data_file,
"data/raw_data.csv",
format = "file"
),
tar_target(
raw_data,
read_csv(raw_data_file, col_types = cols())
),
tar_target(
data,
raw_data %>%
filter(!is.na(Ozone))
),
tar_target(hist, create_plot(data)),
tar_target(fit, biglm(Ozone ~ Wind + Temp, data))
)
このように tar_target() 関数でターゲットを定義し、それをリストにまとめることでパイプラインを定義できるようになっています。個別の関数の意味や使い方についてより詳しくは マニュアル や ドキュメント をご覧ください。
targets の利点
小規模プロジェクトにおける targets の有効性
一見すると targets のようなパイプラインツールは時間の掛かる処理が含まれるプロジェクトや大規模な並列・分散処理を行いたい場合に有益なように思われます。しかし、Miles McBain 氏 はブログ記事 "Benefits of a function-based diet (The {drake} post)." で drake (当時)は小規模なプロジェクトでも有効だと説いています。
一部抜粋して訳します。
当初私は drake に make の簡易版として魅力を感じていました。なぜ make を必要としていたかというと、主に2つの理由がありました。
- 私たちのプロジェクトではほとんど場合、業務データベースから SQL で大きなデータを取ってくるステップがあります。ここでジレンマが生じます。再現性のためにはなるべく頻繁に分析パイプライン全体を実行したいのですが、他の人と共有されているDBに全く同じデータを何度も取りにいくのは迷惑になるのでやりたくないのです。つまりキャッシュが欲しかったわけですが、特にミニマルで明示的なキャッシュ管理が良いと思っていました。
- 私は以前から分析パイプラインを構造化してまとめ上げられるような共通フレームワークを探し求めていました。私は数年にわたって様々な R プロジェクトのテンプレートツールを試してきましたが、フォルダ構造が複雑すぎるものは好きになれませんでした。どうしてもその構造にぴったり合わせられないところが出てきてしまうのです。
幸い drake はその両方に応えるばかりでなく、それ以上のものでした。
drake が気になっているという人からよく出る質問は「いつごろから drake を使う意味が出てくるでしょうか」「〇〇のようなことしかしていないのですが、drake は役に立つでしょうか?」といったものです。
私の見解はこうです:
drake を利用したデータ分析パイプラインのアプローチはプロジェクト規模の大小を問わず有効です。なぜなら
- 無用な計算時間が避けられること
- インタラクティブな開発フローでよく起きる種類のバグがなくせること
- 扱いやすいデバッグ用の "点検パネル" が付いてくること
- わかりやすいプロジェクト構造・コード構造が促されること
によって作業が速くなるからです。
しかし、drake さえ使えばこれらすべてが得られるというわけではありません。正しい方針が与えられるのは確かですが、このような恩恵を十分に受けられるワークフローを確立できるかどうかはまだなお自分次第です。そして私の考えでは、多くの人が詰まってしまうのはこの最初のステップを踏み出すところだと思っています。
ここで挙げられた drake の利点はそのまま targets にも当てはまります。
実のところ私が targets に興味を抱くようになったのもこの記事がきっかけでした。
targets でのデータ共有
分析プロジェクトにおけるデータの共有には悩ましいところがあります。 データをCSV形式などのファイルでソースコードとともに Git で管理・共有するのが最も手軽で確実です。 しかし Git はソースコードを管理するためのツールなので、例えばデータのサイズが大きい場合などにはあまり適していません。
そこで、データは Google BigQuery のようなデータウェアハウスや Amazon S3 のようなオブジェクトストレージに保存しておき、ソースコードとは別に共有する方法が考えられます。このとき、各々のローカル分析環境では元データをダウンロードしてから分析処理を実行する必要があります。
targets プロジェクトではそのようなダウンロード処理をパイプラインの一部に含めることができます。これには次のような利点があります。
- ダウンロードしたデータをローカル環境のどこにどのような形式で保存するかが標準化されている
- 依存関係管理により、データをダウンロードしてからその後の分析処理に進むという実行順序が保証される
- キャッシュ機構により、ダウンロードが既に済んでいる場合は実行がスキップされる
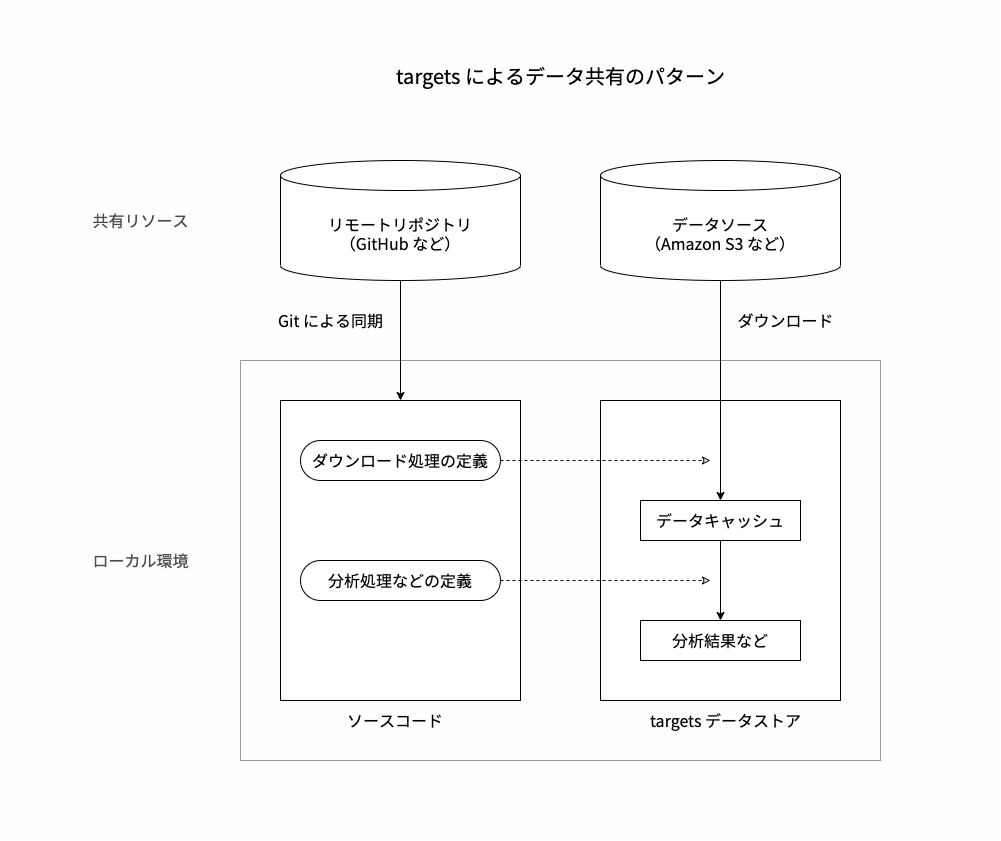
targets によるデータ共有
McBain 氏のブログ記事では、ダウンロードしたデータがキャッシュされることによって頻繁なパイプライン実行が可能になり、再現性のある処理が開発しやすいことが利点に挙げられています。しかしそれと同時に、データウェアハウスやオブジェクトストレージを単一のデータソースとして同一のデータをチームで共有できることも大きな利点だと私は考えています。
関数によるコードの構造化
コードが長く複雑になってきたとき、ある程度のまとまりに分けて書くと読んだときに理解しやすくなります。 targets では関数を単位として分析パイプラインを構造化することが推奨されています。
関数を使わなくてもスクリプトファイルを分割することは可能ですが、どこでどのようなオブジェクトが定義されているかの把握が難しく、互いの関係が複雑化してしまいます。関数を使ってコードを分割することによって互いを疎結合に保ち、保守性を高めることができます。
この点について targets ユーザーマニュアルでは次のように説明されています
4.2 関数
関数は多くのシステムでコードの構成単位として使われています。 関数を使うことでコードを考えやすくなり、複雑なアイデアを扱いやすい小さなかたまりに分解することができるようになります。 関数はコンテキストから離れて独立に開発・テストすることができるので、頭の中でお手玉をするように他のことを気にする必要がなくなります。 ワークフロー全体のコンテキストから見ると、関数は各ステップをわかりやすく表した便利な省略記法になります。
さらに、関数はデータサイエンスを表す良いメンタルモデルになります。 データ分析のワークフローはデータセットから分析結果へ、分析結果からサマリーへといった変形の連続です。 実際、データサイエンスの関数はたいてい次の3つのどれかに分類できます:
- データセットを処理する
- データセットを分析する
- 分析結果をサマリーにまとめる
(原文)
targets を採用することによって単純なスクリプト処理のプログラミングスタイルから一歩先へ進み、関数によってコードを分割して構造化する指針が得られます。
R Markdown との相性
targets が前身の drake と大きく異なる点の一つに tarchetypes パッケージの存在があります。このパッケージに含まれる tar_render() 関数を使うと R Markdown 文書のレンダリング処理を分析パイプラインへ自然に組み込むことができます。
R Markdown を使っていると分析処理の内容は変えずに一部の文章表現やスタイルを調整したい場合がよくあります。targets のキャッシュ機構によって重い処理をスキップできるので、気軽に修正と再レンダリングを繰り返すことができるようになります1 。
また、まもなく Target Markdown 機能がリリースされる予定になっています2。これを使えば R Markdown 文書の内部で targets パイプラインを定義することが可能です。これによってより文書とコードを一体のものとして扱えるようになると期待されます。
targets が推奨する関数型のプログラミングスタイル
targets にはここまで述べてきたような利点があるものの、良い構造化のためには関数型プログラミングのプラクティスを理解し取り入れる必要があります。ここでその基本的な考え方をまとめておきます。
R と関数型プログラミング
R と関数型プログラミングについては Hadley Wickham "Advanced R, Second Edition" で次のように説明されています。
関数型プログラミング言語
どんなプログラミング言語にも関数はあります。では言語が関数型であるとはどういうことでしょうか? 何をもって関数型とするかという定義について厳密には様々なものがありますが、いずれも2つの共通点があります。
第一に、関数型言語には第一級関数があります。 第一級関数とは、他のデータ構造と同様の振る舞いをする関数のことを言います。 R についていうとこれはベクトルに対してできることが関数に対してもできるという意味になります。 例えば関数を変数に代入したり、関数をリストに格納したり、関数を他の関数の引数に渡したり、関数の中で関数を生成したり、関数の戻り値として関数を返すこともできます。
第二に、多くの関数型言語では関数が必ず純粋であることが求められます。 関数が純粋であるとは、次の2つの条件を満たすときに言います:
- 関数の出力が入力値のみに依存すること。これは、同じ入力値で関数を呼び出せば同じ出力が得られるということです。
runif(),read.csv(),Sys.time()などは異なる値を返す可能性があるので、これに当てはまりません。- 関数が副作用を持たないこと。副作用とはグローバル変数を変更したり、ディスクにデータを書き込んだり、画面に何か表示したりすることなどです。
print(),write.csv()や<-はこれに当てはまりません。純粋な関数は内容の理解が容易になりますが、明らかに不便な面もあります。 乱数も生成できず、ディスクからファイルを読み取りこともできない中でデータ分析を行うところを想像してみてください。
厳密に言うと、R は関数型プログラミング言語ではありません。R の関数は必ずしも純粋とは限らないからです。 しかし、関数型のスタイルをコードに取り込むことはできます。 純粋関数を書くことは必須ではありませんが、そうしたほうが良い場合は多いでしょう。 私の経験では完全に純粋な関数と全く純粋でない関数に分けて書くと、そのコードは理解しやすく後の状況に応じて拡張しやすいものになる傾向があります。
(原文)
このように、関数型プログラミングのスタイルを R のプロジェクトには取り込むには純粋関数とそれ以外の区別と使い分けが肝心となります。
targets と関数の副作用
targets ユーザーマニュアル では副作用について次のように述べられています。
6.2 副作用
純粋関数がそうであるように、良いターゲットとは単一の値を返し副作用を持たないものです(出力ファイルのターゲット については例外で、ファイルを作成してそのパスを戻り値に返します)。
data()やsource()の呼び出しはグローバル環境を変更してしまうので避けてください。(原文)
もしもターゲットに副作用があると、キャッシュを使ってスキップした際に後続の結果が変わってしまう可能性があります。ターゲットが戻り値を返す以外にシステムの状態を変更することで暗黙のうちに後続の処理に影響を与えているかもしれないからです。
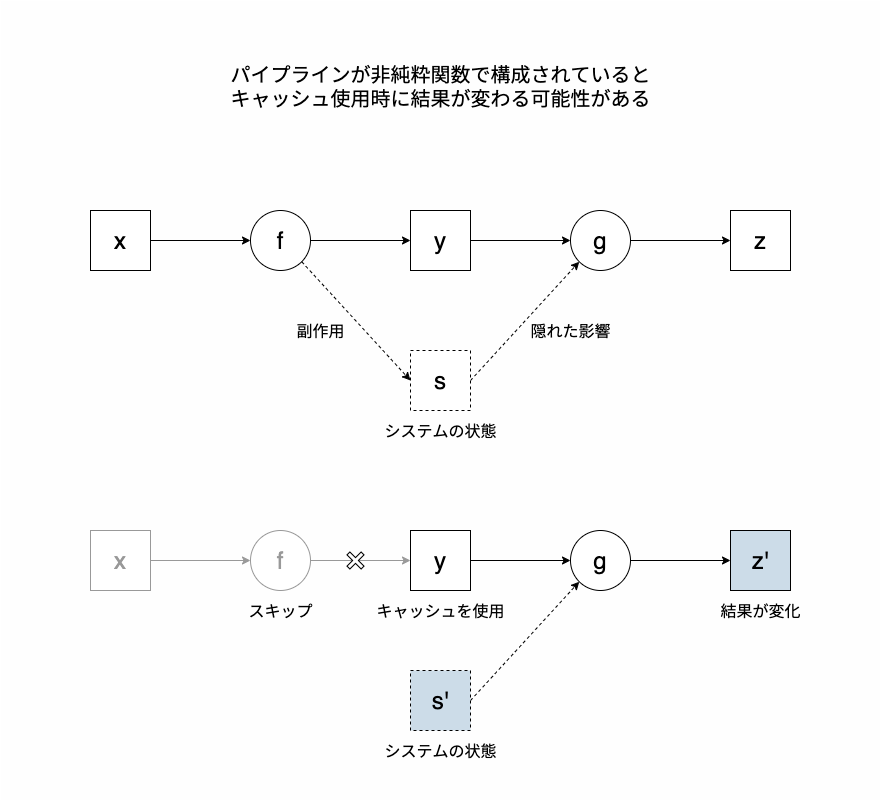
副作用のためキャッシュが機能しないパイプライン
targets さえ使っていれば自動的に副作用を避けられるということではないので、これはユーザー自身の責任で行います。例えばグローバル変数を変更しない、setwd() で作業ディレクトリを変更しない、library() でサーチパスを変更しない、どうしても状態変更が必要なときは withr パッケージ を使って一時的なものにするなどの工夫が必要となります。
しかし、完全に純粋関数だけで分析パイプラインを構築することは現実的ではありません。当然ながらデータ分析プロジェクトでは何らかの分析結果をファイルに保存するのが普通ですが、ファイルへの書き込みは副作用なので純粋関数では実現できません。入力ファイルについても同様で、関数がファイルの内容を読み取るということは引数以外の要因に影響を受けるということなので、その関数は純粋ではありません。
targets にはこうしたファイル入出力を扱うための専用の仕組みとして tar_target() 関数の format = "file" オプションが用意されています。これを利用するとファイルが変更されたときにキャッシュが無効化されて入出力処理が再実行されるようになります。
関数が純粋かどうかを気にするのは面倒に思われるかもしれませんが、できるだけ純粋な関数を組みわわせて処理を構成していくのは targets を使うかどうかに関わらず良いプラクティスです。 そうすることで複雑な問題を小さな部分に分解して個別に対処していくことができるようになるからです。
まとめ
- targets は R のデータ分析プロジェクト用パイプラインツールです
- targets は小規模なプロジェクトでも有益です
- targets では関数を定義しそれを組み合わせてパイプラインを構成するプログラミングスタイルが推奨されています
- 純粋関数とそうでない関数の区別を意識して取り扱うことが重要です
本記事では targets の有効性や活用方針を確認するに留め、具体的なコードの書き方はあまり扱いませんでした。機会があれば他の記事で補完していきたいと思います。
Footnotes
-
knitr にもキャッシュ機能は存在するものの、複雑なのでむやみに使うべきでないと作者自身が述べています: https://bookdown.org/yihui/rmarkdown-cookbook/cache.html ↩