パーティションの置換による差分更新
以前の記事 BigQuery 上でデータ変換パイプラインを構築するための SQL の書き方 では、MERGE文を使っていわゆるUPSERT処理を行う方法について紹介しました。
UPSERTとは、差分データの各行に対して、もしユニークキーの値がそれと合致するような行が対象テーブルに存在すればその行を上書き更新(UPDATE)し、存在しなければ新規挿入(INSERT)するという処理のことです。
本記事ではそれよりもシンプルな方法として パーティション置換による差分更新 の実装をご紹介します。
まずはパーティション置換による差分更新とはどのようなものか、例を図で示します。
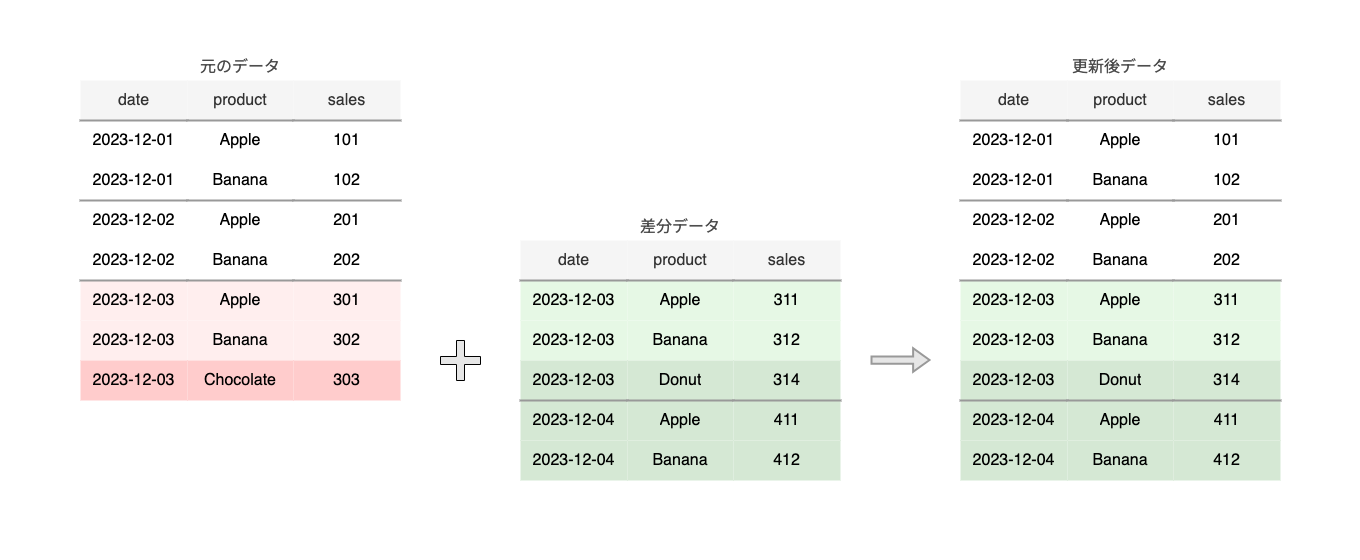
図: パーティションの置換による差分更新の例
前提として
- 更新対象のテーブルは適当なカラム (ここでは日付カラム
date) でパーティショニングされているものとします。 - 差分データは常にパーティション単位(ここでは1日単位)でまとまっていて、それより小さな粒度にはならないものとします。
パーティションの置換による差分更新とは、このような場合に
- 差分データのパーティションと同じ日付のものが既にテーブル内に存在する場合は置換する (図の例では 2023-12-03 のパーティション)
- 存在しない場合はパーティションを追加する (図の例では 2023-12-04 のパーティション)
という単純なものです。
MERGE文による実装
BigQueryでは、上のような処理を次のようなMERGE文で実装することができます:
-- 差分データから更新対象パーティションの日付を読み取り、いったん変数に代入する
DECLARE batch_dates ARRAY<DATE>;
SET batch_dates = (SELECT ARRAY_AGG(DISTINCT date) from `dataset.batch`);
MERGE `dataset.target` T
USING `dataset.batch` S
-- merge_condition で定数 false 述語を使用する
ON FALSE
-- 新しいパーティションの行を挿入
WHEN NOT MATCHED BY TARGET THEN
INSERT ROW
-- 古いパーティションの行を削除
WHEN NOT MATCHED BY SOURCE AND `date` IN UNNEST(batch_dates) THEN
DELETE
ここで dataset.target は更新対象のテーブルを、dataset.batch は差分データが格納されたテーブルをそれぞれ表すものとします。
パーティションのプルーニング
上のMERGE文ではパーティションのプルーニングが行われます。
つまり、元のテーブルから削除される行は列 date で絞り込まれているため、他の変更のないパーティションのデータに対して余計なスキャンが発生しません(上の図では 2023-12-01 と 2023-12-02 のパーティションが該当します)。これによって料金と処理時間を節約することができます。
定数 false 述語の効果
通常MERGE文ではソーステーブルと対象テーブルの行を比較するため内部的にJOIN操作が行われますが、
MERGE ... USING ... ON FALSE ...
のようにマージ条件が定数 FALSE となっている場合はJOINが行われません。
この最適化のことを 定数 false 述語 と呼びます。
このおかげで、単にパーティションを置換する目的でMERGE文を使っても無駄なJOIN操作で処理効率が落ちることがありません。
ユニークキーによるUPSERTとの比較
テーブルの差分更新には1行ずつユニークキーの値を比較してUPSERTする方式も用いられます。筆者も実際によく利用してきました。 しかし、定期的なバッチ処理で外部システムから分析基盤へのデータ連携を行うような場合、パーティションの置換による差分更新のほうが適している場面が多いと感じています。
UPSERT方式の難点に一つ挙げられるものとして、過去のデータを訂正したいときに、差分データを修正してバッチ処理を再実行しても行の削除に対応できないという問題があります。
上の図の例で言うと、元のデータに含まれていた date = "2023-12-03" の product = "Chocolate" の行を削除するという変更がUPSERT方式では実現できません。
また、外部から分析基盤へと連携されるデータは必ずしも期待した通りの品質が担保されているとは限りません。 ユニークキーとして利用しているカラムに一意性を満たさないデータが渡されてくる可能性もないとはいえませんし、 長期間にわたる運用の中で連携データに後方互換性のない仕様変更が行われる可能性も考えられます。 そして、分析系システムは入力データに厳密性を要求せず、想定から外れたデータが与えられえてもパイプラインは停止せずに動作し続けることが期待される傾向にあります。
それらを考慮すると、一見UPSERT方式で差分更新できそうであってもパーティションの置換で対応するのが妥当な選択になることが多くあるかと思います。
まとめ
- MERGE文でパーティションの置換によるテーブルの差分更新が実現できます。
- パーティションのプルーニングと定数 false 述語によって効率的な処理が可能です。
- データパイプラインにおけるテーブルの差分更新ではUPSERTよりもパーティションの置換のほうが適している場面がよくあります。
参考資料
BigQuery 上でデータ変換パイプラインを構築するための SQL の書き方 | terashim.com
以前の記事です。MERGE文によるUPSERT方式の差分更新について説明しました。
DML を使用したパーティション分割テーブルデータの更新 | BigQuery | Google Cloud
『merge_condition で定数 false 述語を使用する』のセクションにこの構文の詳しい説明があります。
Data manipulation language (DML) statements in GoogleSQL | BigQuery | Google Cloud
MERGE文のリファレンスです。
西田圭介 [増補改訂]ビッグデータを支える技術 ――ラップトップ1台で学ぶデータ基盤のしくみ:書籍案内|技術評論社
『第5章 ビッグデータのパイプライン』でパーティションの置換によるデータ更新について触れられています。